信息技术的不断发展,使得全球的数据量呈现出爆炸性增长趋势。IDC报告表明,2013年全球数据量为4.4ZB, 2020年全球的数据总量将达到40ZB。
对于企业来说,其数据中心也同样面临着成倍增长的数据所带来的保护难题。那么,要对这种海量数据实施保护,最简单的解决方案无疑就是数据拷贝。然而,数据拷贝存在一个致命的问题,即大量冗余数据的存在。IDC的研究报告指出,在企业新增的数据中,来自于文件数据的冗余就占据了75%的比例,而块级别冗余甚至达到了95%。
这种大规模的数据冗余,会对企业数据中心的后续管理带来更多令人头疼的烦恼。数据量的迅速增长,不仅造成了存储资源的浪费,更严重的问题在于拷贝时,将会对网络环境造成极大的压力。由于数据中心往往作为其他平台的支撑体系,这种大量冗余数据对网络带宽的占用,就导致整个系统效率的下降。
面对这种令管理者困扰的难题,爱数AnyBackup提供了一种可以帮助企业减少冗余,降低网络带宽占用,提高企业效率的解决方案,即AnyBackup第三代重复数据删除技术。
AnyBackup第三代重复数据删除:三大优势
一、从备份源头说起:源端重复数据删除
AnyBackup第三代重复数据删除技术(以下简称为“第三代重删”),是一种源端重复数据删除技术,在数据源头就将冗余数据进行识别并抛弃,只筛选出新增数据进行备份。也就表明,网络中传输的数据只有筛选过后的新增数据。
AnyBackup第三代重删,在每个客户机上对所要备份的数据进行智能感应并分割,将其打碎成数据片断,然后将该数据片断采取特殊算法计算出唯一标识ID。AnyBackup客户端将会联系AnyBackup服务器进行该唯一标识ID的查询,如果查找到该标识,则说明该片段是冗余数据,如果并未找到,则说明该数据是新增数据,AnyBackup客户端会将该段数据进行压缩后进行传输。
和传统的备份方案进行比较后发现,源端重复数据删除,将去冗余技术在数据发送之前进行,从而在最大程度上减少了需要备份传输的数据,即减少了网络带宽的占用。
二、冗余粒度可控:可调节的重复数据删除粒度
AnyBackup第三代重删,对于重复数据识别粒度可以自行设置,从而更好地满足现实数据保护需求。对于粗粒度,支持文件级别冗余数据识别;对于细粒度,AnyBackup第三代重删在备份过程中,通过智能感应打碎数据块。AnyBackup第三代重删可以识别出两次备份数据中相同的部分,并在该位置将数据进行打碎。除此之外,AnyBackup第三代重删对于打碎数据的粒度也是可控的,支持不同KB级别的打碎粒度:大粒度打碎可以减少唯一标识查找次数,加快备份速度,小粒度打碎可以更精准识别出冗余数据。
三、策略减少冗余:任务级别的重复数据删除
对于大部分重复数据删除产品来说,普遍使用的是全局的重复数据删除技术,就是将所有的数据源不区分类型,进行冗余识别。这种方式所带来的弊端也是显而易见的。比如,数据块ID库增长不可控,且随着ID库的增长将会造成冗余查询机制的减慢,最终导致备份效率的降低。
根据最新的实验室调查结果发现,在两个不相干或不同类型的任务中,在查询冗余过程时,基本不会出现相同或相似数据。这也就意味着两个任务之间,完全没有块粒度级别冗余数据。基于此,AnyBackup第三代重删采取了任务级重复数据删除。
AnyBackup第三代重删所支持的任务级别重删,可以识别出任务范围内的冗余数据,旨在将不同应用类型的备份任务在指定的范围内进行ID查询,这样的查询机制在不影响查询冗余效果的基础上,使其查询过程可控,加速查询效率,降低内存占用。更重要是将整个数据中心的重删性能、重删比率及所需资源均衡至一个最佳值,达到最优效果。
用数据说话:AnyBackup重复数据删除速度比较
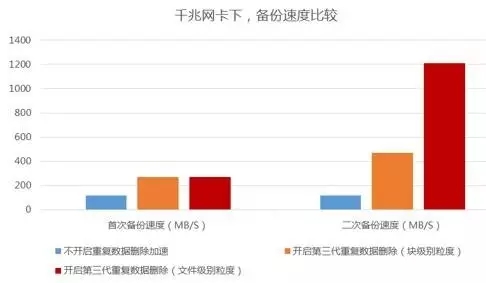
为了测试AnyBckup第三代重删在窄带宽环境下对于速度的提升优势,仅针对于普通文件备份,分别开启重删加速以及不开启重删加速进行对比测试。具体测试时,在千兆网卡环境下,对于一万多个文件总计3T左右数据进行备份测试。此次测试使用同一个备份环境,将可变因素降到最低,以确保测试的准确性。
首次备份过程中,开启第三代重删功能,文件备份的速度是不开启该功能备份速度的2倍;二次备份过程中,不开启第三代重删技术,其备份速度和第一次没有变化。但是开启第三代重删功能时,其备份速度大幅提升,细粒度的去重加速是普通备份速度的4倍,粗粒度的文件级重删加速更是将备份速度提升到不开启重删加速的9倍。
除了对于数据拷贝产生的冗余识别之外,AnyBackup第三代重删在其他备份场景中也表现极好,比如VMware环境中结合块修改跟踪机制发挥出了巨大的优势,可以识别并删除掉99%的冗余数据,实现TB级别数据的分钟级恢复,进一步实现数据转移和容量优化。
AnyBackup第三代重删技术采取三大优势,将备份传输前的数据量降到最低,使得海量数据即使在窄带环境下,依然可以高效率保护数据。